AI-Ready Data: A Primer on What AI Agents Need to Excel
In late 2023, OpenAI launched ChatGPT, and many of us had an “Aha!” moment. It felt revolutionary. Fast forward to today, where AI has become a strategic driver across every major industry. Companies all over the world are investing billions into AI initiatives, often without immediate ROI. Why? Because they see what’s coming next.
We’re now in a new era of AI that spans across:
Each of these technologies works differently. But they all rely on the same foundation: structured, trustworthy, quality data.
Traditional software is predictable. It is given fixed inputs, it runs predefined logic, and you get consistent output. Engineers can test it, debug it, and expect the same result every time.
AI works differently, especially when it involves large language models (LLMs) or RAG (retrieval-augmented generation). The output of AI systems is probabilistic, not deterministic. And it depends heavily on the context and quality of the data that powers it.
A mislabeled data point or outdated record in one part of the data pipeline can ripple across the system and throw off the output entirely.
Overall, becoming AI-ready as a business means putting data at the center of the conversation.
While there is no single, universally accepted definition of AI-ready data, our perspective as an AI data-ready marketplace is the following:
AI-ready data is data that can be directly accessed, understood, and used by AI systems immediately.
AI-ready data is information that AI systems can use immediately because it’s already clean, structured, and well-documented. It’s characterized by:
For data providers, this means packaging their data products in formats AI can consume directly. For data consumers, it means choosing data products that are AI-ready out of the box, so teams spend less time fixing data, and more time building.
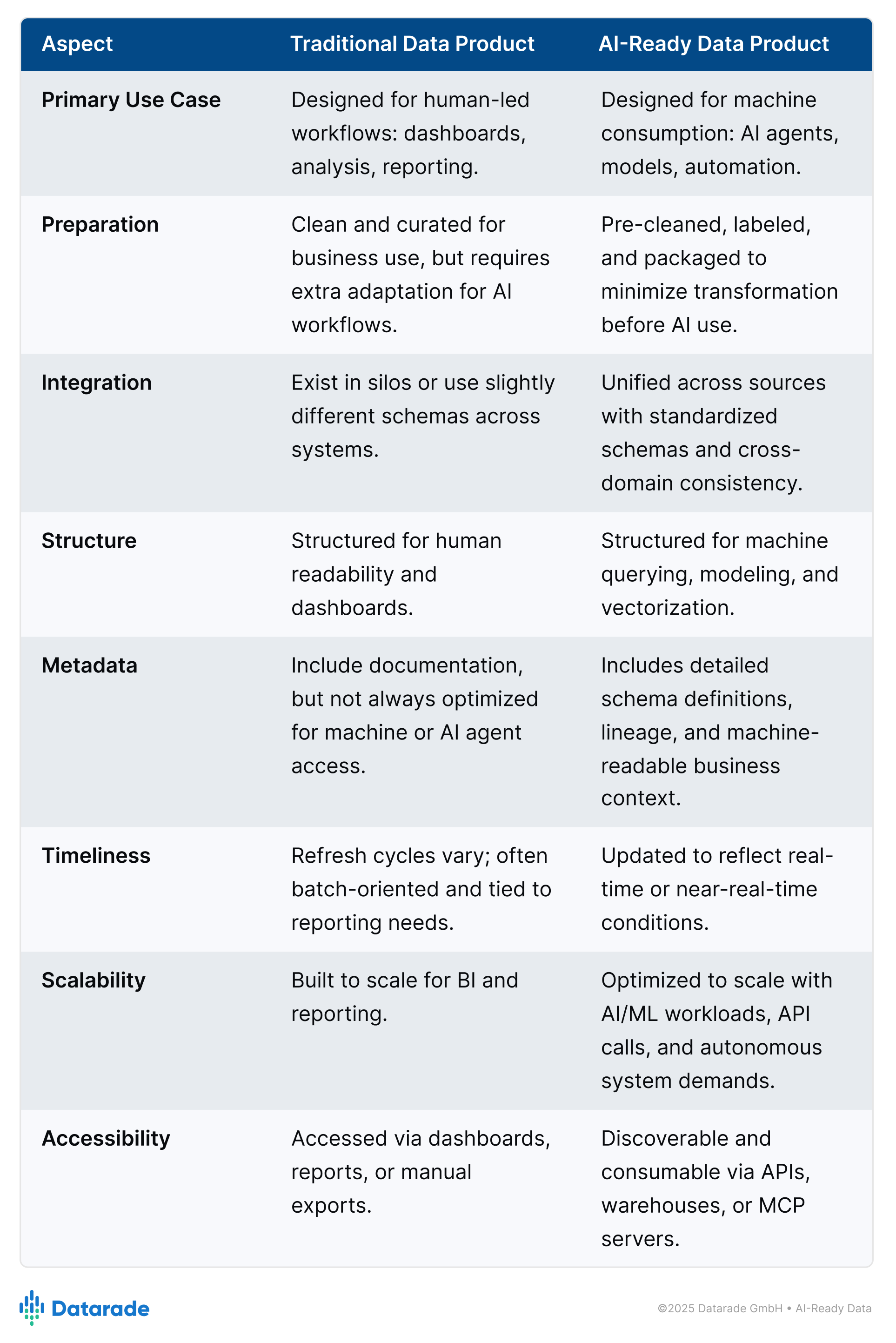
A traditional data product is a curated, trusted package of data that includes ownership, documentation, quality checks, and can be consumed through SQL, files, or APIs. Many traditional data products are typically designed for human-led workflows, not for AI autonomous systems.
An AI-ready data product, on the other hand, is structured so AI systems can use it immediately. It comes in machine-readable formats, enriched with metadata, interoperable with standards, and includes built-in governance for bias and compliance. This is where their purpose and design set them apart:
What makes a data product AI-ready? As we said before, AI systems need data that is structured, understandable, traceable, accessible, and safe to use.
This is why we define AI-readiness through 5 core principles that align with how modern AI tools consume and act on data.
1. Structure & cleaning
AI-ready data is structured and stable by design. If an AI agent has to guess what a column means or deal with inconsistent schemas across sources, it’s already starting at a disadvantage. Missing values are addressed, labels are consistent across the dataset, and duplicates are removed before they create noise. The same applies for ML training (normalized values) and GenAI pipelines (well-structured context).
2. Metadata & context
AI systems cannot assume business logic; they have to be taught. This is where context becomes critical. AI-ready data products include rich metadata and documentation that define each field, clarify how it should be used, and show how it connects to other elements in the system. For GenAI, that metadata might be the difference between a vague summary and an accurate, context-aware answer. For ML, it prevents misinterpretation of features.
3. Traceability & provenance
AI-ready data is fully traceable: every transformation and dependency is recorded. If an AI agent makes a flawed decision, teams must be able to trace the result back to its original source, understand any transformations applied, and reproduce the outcome for debugging. Provenance is critical as well in ML pipelines and GenAI (knowing which documents were retrieved).
4. Discoverability & access
AI-ready data is findable, linkable, and queryable. If a dataset is buried in a spreadsheet, locked in a silo, or requires internal backchannels to access, it’s not AI-ready. To support AI agents, data must be accessible via APIs, catalogs, or interfaces like MCP (Model Context Protocol) servers. For ML, this means consistent formats for training; for GenAI, it means retrieval-ready data in machine-readable formats like JSON-LD, RDF, or Parquet.
5. Governance & compliance
AI-ready data must be safe to use legally, ethically, and operationally. That means clear usage rights, governance policies, and compliance with frameworks like GDPR or CCPA, along with technical safeguards like access controls, encryption, and audit logs. It must also be regularly assessed for bias to ensure fairness and accountability. If data isn’t safe to use by both humans and AI agents, it’s not ready for real-world AI.
.png)
At Datarade, we believe AI-readiness is the next chapter of the data economy. The success of tomorrow’s AI systems won’t just depend on how they’re trained, but it will depend on what they’re fed.
That’s why Datarade is the AI data-ready marketplace: if AI is going to act, decide, and deliver, the data behind it has to be ready for the job.
In late 2023, OpenAI launched ChatGPT, and many of us had an “Aha!” moment. It felt revolutionary. Fast forward to today, where AI has become a strategic driver across every major industry. Companies all over the world are investing billions into AI initiatives, often without immediate ROI. Why? Because they see what’s coming next.
We’re now in a new era of AI that spans across:
Each of these technologies works differently. But they all rely on the same foundation: structured, trustworthy, quality data.
Traditional software is predictable. It is given fixed inputs, it runs predefined logic, and you get consistent output. Engineers can test it, debug it, and expect the same result every time.
AI works differently, especially when it involves large language models (LLMs) or RAG (retrieval-augmented generation). The output of AI systems is probabilistic, not deterministic. And it depends heavily on the context and quality of the data that powers it.
A mislabeled data point or outdated record in one part of the data pipeline can ripple across the system and throw off the output entirely.
Overall, becoming AI-ready as a business means putting data at the center of the conversation.
While there is no single, universally accepted definition of AI-ready data, our perspective as an AI data-ready marketplace is the following:
AI-ready data is data that can be directly accessed, understood, and used by AI systems immediately.
AI-ready data is information that AI systems can use immediately because it’s already clean, structured, and well-documented. It’s characterized by:
For data providers, this means packaging their data products in formats AI can consume directly. For data consumers, it means choosing data products that are AI-ready out of the box, so teams spend less time fixing data, and more time building.
A traditional data product is a curated, trusted package of data that includes ownership, documentation, quality checks, and can be consumed through SQL, files, or APIs. Many traditional data products are typically designed for human-led workflows, not for AI autonomous systems.
An AI-ready data product, on the other hand, is structured so AI systems can use it immediately. It comes in machine-readable formats, enriched with metadata, interoperable with standards, and includes built-in governance for bias and compliance. This is where their purpose and design set them apart:
What makes a data product AI-ready? As we said before, AI systems need data that is structured, understandable, traceable, accessible, and safe to use.
This is why we define AI-readiness through 5 core principles that align with how modern AI tools consume and act on data.
1. Structure & cleaning
AI-ready data is structured and stable by design. If an AI agent has to guess what a column means or deal with inconsistent schemas across sources, it’s already starting at a disadvantage. Missing values are addressed, labels are consistent across the dataset, and duplicates are removed before they create noise. The same applies for ML training (normalized values) and GenAI pipelines (well-structured context).
2. Metadata & context
AI systems cannot assume business logic; they have to be taught. This is where context becomes critical. AI-ready data products include rich metadata and documentation that define each field, clarify how it should be used, and show how it connects to other elements in the system. For GenAI, that metadata might be the difference between a vague summary and an accurate, context-aware answer. For ML, it prevents misinterpretation of features.
3. Traceability & provenance
AI-ready data is fully traceable: every transformation and dependency is recorded. If an AI agent makes a flawed decision, teams must be able to trace the result back to its original source, understand any transformations applied, and reproduce the outcome for debugging. Provenance is critical as well in ML pipelines and GenAI (knowing which documents were retrieved).
4. Discoverability & access
AI-ready data is findable, linkable, and queryable. If a dataset is buried in a spreadsheet, locked in a silo, or requires internal backchannels to access, it’s not AI-ready. To support AI agents, data must be accessible via APIs, catalogs, or interfaces like MCP (Model Context Protocol) servers. For ML, this means consistent formats for training; for GenAI, it means retrieval-ready data in machine-readable formats like JSON-LD, RDF, or Parquet.
5. Governance & compliance
AI-ready data must be safe to use legally, ethically, and operationally. That means clear usage rights, governance policies, and compliance with frameworks like GDPR or CCPA, along with technical safeguards like access controls, encryption, and audit logs. It must also be regularly assessed for bias to ensure fairness and accountability. If data isn’t safe to use by both humans and AI agents, it’s not ready for real-world AI.
At Datarade, we believe AI-readiness is the next chapter of the data economy. The success of tomorrow’s AI systems won’t just depend on how they’re trained, but it will depend on what they’re fed.
That’s why Datarade is the AI data-ready marketplace: if AI is going to act, decide, and deliver, the data behind it has to be ready for the job.
-modified%20(1).png)



.png)